Katさんが、もっと簡易な解析でよければ、Rだけでかけるよと、VSOLJ-MLに投稿されていたので、試してみました。
まず、データを用意します。
vsolj databaseから、χ Cygのデータを落とします。
cygchi.stdを、DBVS2000を使って、日付の部分をJDに変えます。
DBVS2000フォルダーにcygchi.stdを移動させてから、コマンドプロンプトを立ち上げて、DBVS2000のホルダーで、以下にコマンドを実行します。
pack cygchi.std | tojd > cygchi.jd
できたファイルから、何等以下の観測とかを取り除くのは、Excelでやりました。
ついでに、等級も1/10にして、普通の表示にしておきました。
名前をつけて保存から、csv形式を選んで、cygchi.csvとしてセーブします。
#ここも、スクリプトでやるのも良いのですが、Rオンリーでなく、データの加工にはExcelを適材適所で使うのは、大学の授業譲りです。
#Excelは、データビュアーとしてや、ちょっとした加工に最適、データの解析には使ってはいけない(w
Rを立ち上げて、作業フォルダーをcygchi.csvを置いたフォルダーに変えてから、データを読み込みます。
>d <- read.csv("cygchi.csv", header=F)
データの一部を表示させると、
> d[5000:5010,]
V1 V2 V3
5000 42533.24 4.9 Sem
5001 42534.25 4.8 Kob
5002 42539.11 4.5 Mir
5003 42539.13 4.8 Mto
5004 42540.12 4.5 Num
5005 42540.13 4.8 Mto
5006 42540.15 4.8 Hmo
5007 42540.18 4.7 Kob
5008 42540.21 5.0 Hok
5009 42540.24 4.7 Knw
5010 42543.11 4.7 Knw
こんな感じです。
d$V1がJD、d$V2が等級になります。
で、加藤さんの作られたRのソースをcopy&pasteして入力します。
pergrm <- function(d,start,end,div) { d$V2 <- d$V2 - mean(d$V2) p <- seq(start,end,length=div+1) pw <- numeric(div+1) for (i in 1:(div+1)) { tp <- p[i] ph <- ((d$V1/tp) %% 1)*pi*2 ss <- sin(ph) cc <- cos(ph) s <- sum(d$V2*ss)/2 + sum(d$V2*cc)/2 pw[i] <- s } return(data.frame(period=p,power=pw)) }
s <- sum(d$V2*ss)/2 + sum(d$V2*cc)/2の部分、エラーが出たので、改変したのですが、合ってますか?
(追記)合ってませんでした。下記の修正版参照のこと。
ちなみに、さくっと、d$V2 <- d$V2 - mean(d$V2)みたいに記述できるのがRのいいところですね。等級の平均を求めて、各データから引いています。
p <- seq(start,end,length=div+1)のも、Rらしいです。
startからendまで、div分割したデータ列を作っています。
ループを回さないでいいのです。
#あ、でも、p <- seq(start,end,(end-start)/div)って、書かないのはなんでだろう?
準備できたので、計算です。
> pgm <- pergrm(d,300,800,2000)
> plot(pgm,type="l")
> pgm$period[which.max(pgm$power)]
[1] 410.5
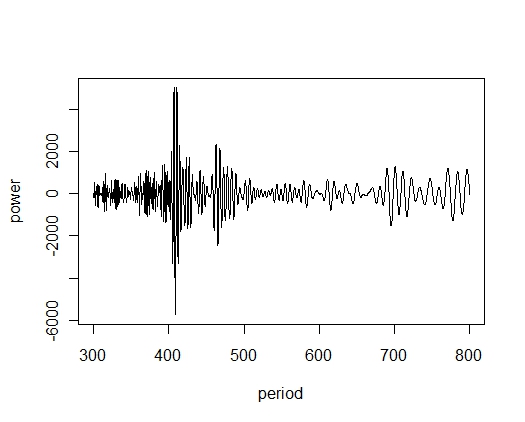
pergramに指定しているのは、データ、解析する周期の最小値、周期の最大値、その間をいくつに分けるかです。
カタログ値は、408.05日ですが、こっちのほうが正しいのかも??
いや、もう少し、短い周期も同じくらいの高さですね。
>plot(pgm,type="l", xlim=c(400, 420))
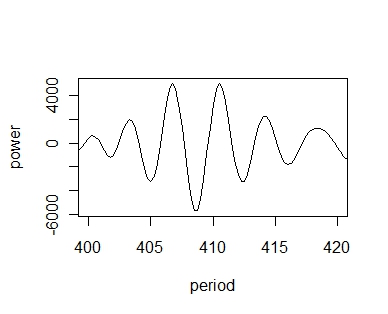
#406.75が5002.1628で、410.5が5004.5893ですか。
408日付近は、逆に、谷になってますが、はて?
もう少し、細かく解析したければ、
pgm <- pergrm(d,400,420,2000)
とでもして、すぐに再解析できます。
こういうインタラクティブにやれるところが、Rでやる時の醍醐味です。
データの大雑把な傾向を知ろうという時等に、さくっとできます。
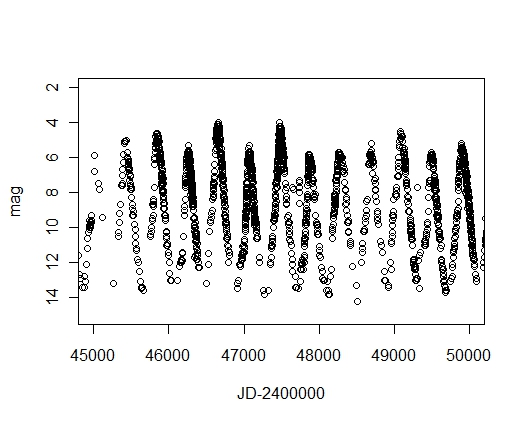
ついでに、光度曲線も書いてみましょう。
plot(d$V1, d$V2, xlim=c(45000, 50000), ylim=rev(c(2, 15)), xlab="JD-2400000", ylab="mag")
Rのインストール方法は、googleと沢山hitすると思うので、各自、googleってください。
#わたしは、普段使う、Windows7、OSX, Ubuntu全てに、Rを入れています。
#なんで、iPad2では動かないんだろう(w